This document describes how to view the archived logs using the AWS (Amazon Web Services) Management Console. Once a user configures to archive logs to a particular AWS S3 bucket (see Archive Logs for more details on how to archive logs), OpsRamp forwards logs related to the tenant to the configured storage bucket in compressed JSON format (.json.gz).
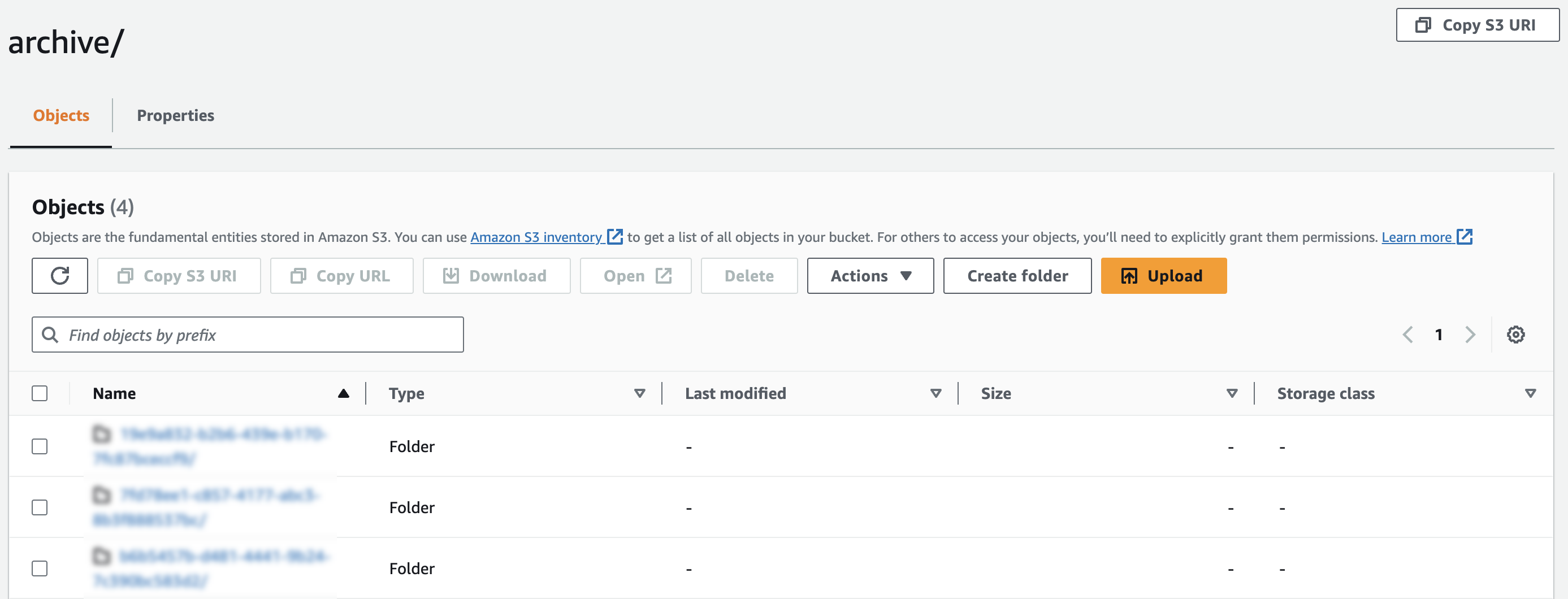
Archived logs are stored in a storage bucket with the following directory structure:
/archive/<tenantUUID>/<YYYY-MM-DD>/<Hour>/<tenantUUID>_Archive_<UnixTimestamp>.json.gz
Where,
- Tenant UUID - Indicates to which tenant these logs belong and which tenant archiver is configured.
- YYYY-MM-DD & Hour - Indicates the date and time at which logs are archived.
- UnixTimestamp - Indicates the Unix timestamp in nanoseconds at which archived log files are created.
Once you download and unzip the JSON log file, the log file contains below format:
[{
"app": "kubernetes",
"cluster_name": "gke-test",
"container_name": "server",
"file_name": "0.log",
"file_path": "/var/log/pods/hipster-shop_checkoutservice-5c5db76c46-8v7kk_3e270ad6-6a9b-4a82-adbd-0ae9c75c5116/server/0.log",
"host": "gke-logs-do-not-delete-pool-2-782c4c71-yh4y",
"level": "Info",
"logtag": "F",
"message": "{\"message\":\"order confirmation email sent to \\\"someone@example.com\\\"\",\"severity\":\"info\",\"timestamp\":\"2023-01-03T09:48:44.307139881Z\"}",
"namespace": "hipster-shop",
"pod_name": "checkoutservice-5c5db76c46-8v7kk",
"restart_count": "0",
"stream": "stdout",
"time": "2023-01-03T09:48:44.30743047Z",
"uid": "3e270ad6-6a9b-4a82-adbd-0ae9c75c5116"
}, {
"app": "kubernetes",
"cluster_name": "gke-test",
"container_name": "server",
"file_name": "0.log",
"file_path": "/var/log/pods/hipster-shop_emailservice-b57ddd777-87vlz_c4a1a837-5d86-4fa4-9f15-aa7642ab175a/server/0.log",
"host": "gke-logs-do-not-delete-pool-2-782c4c71-rhqn",
"level": "Info",
"logtag": "F",
"message": "{\"timestamp\": 1672739324.3060913, \"severity\": \"INFO\", \"name\": \"emailservice-server\", \"message\": \"A request to send order confirmation email to someone@example.com has been received.\"}",
"namespace": "hipster-shop",
"pod_name": "emailservice-b57ddd777-87vlz",
"restart_count": "0",
"stream": "stdout",
"time": "2023-01-03T09:48:44.306457496Z",
"uid": "c4a1a837-5d86-4fa4-9f15-aa7642ab175a"
}]Archive Query with AWS Athena
Since the logs reside on an S3 bucket, there are many ways to query with any tool or method that can access the AWS S3 bucket. This section describes how to use AWS Athena to query these logs.
- Log in to AWS Management Console.
- In the AWS Console, navigate to the Amazon Athena service.
- In the Athena console, click Create Table.
- Choose CREATE TABLE from the Create with SQL section.
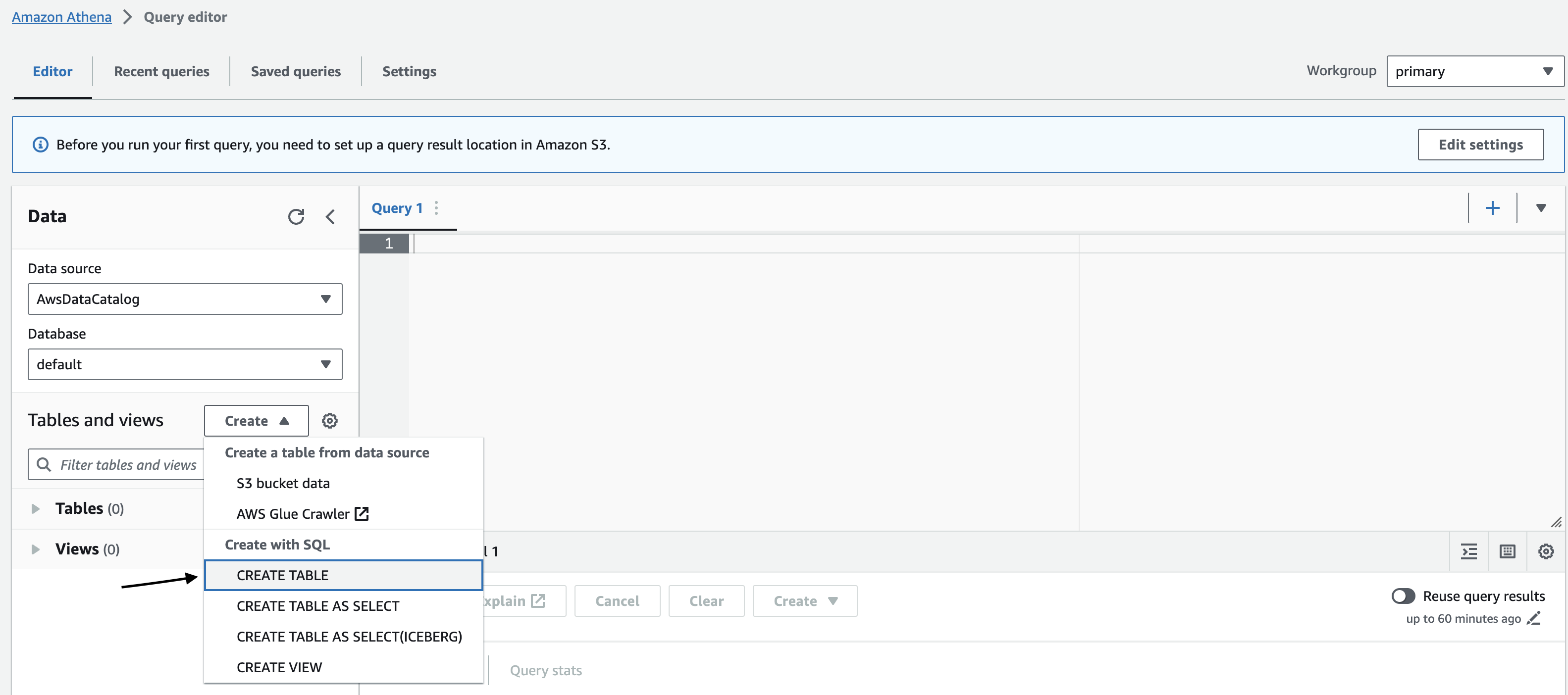
- Provide table schema in the Query editor and change the LOCATION column in the schema with an archival-configured S3 path. For example, s3://archival-logs-bucket/archive/.
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`archive_logs` (`log` string)
LOCATION 's3://<bucket-name>/archive/'
TBLPROPERTIES (
'classification' = 'json',
'write.compression' = 'GZIP'
);- Click Run to execute.
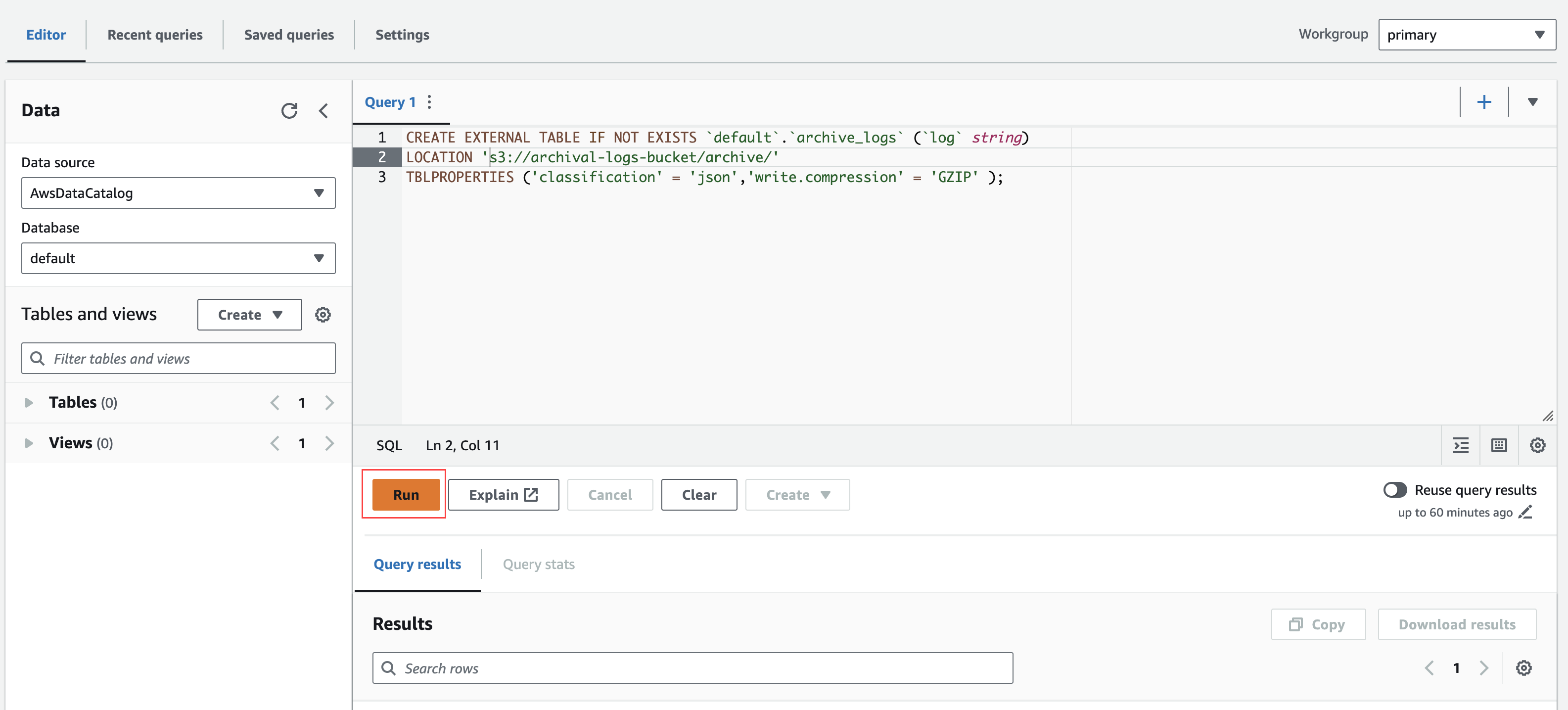
Now that you have a table set up, you can run queries against your archived data.
- In the Athena console, click the Query Editor tab.Write queries to query your archived data.
- Click Run Query to execute the query.The results will be displayed in the console.
The below example shows how to get logs related to a specific source and host matching with a particular string within a given time range:
select js as logs
from archive_logs CROSS JOIN UNNEST(CAST(json_parse(log) AS array<json>)) as t(js)
where
json_extract_scalar(js, '$.source') ='kubernetes' and
json_extract_scalar(js, '$.host')= 'vm2' and
json_extract_scalar(js, '$.message') like '%memorylimiterprocessor%' and
from_iso8601_timestamp(json_extract_scalar(js, '$.time')) > timestamp '2023-09-29 8:50:00' and
from_iso8601_timestamp(json_extract_scalar(js, '$.time')) < timestamp '2023-09-29 8:55:00'
order by from_iso8601_timestamp(json_extract_scalar(js, '$.time'))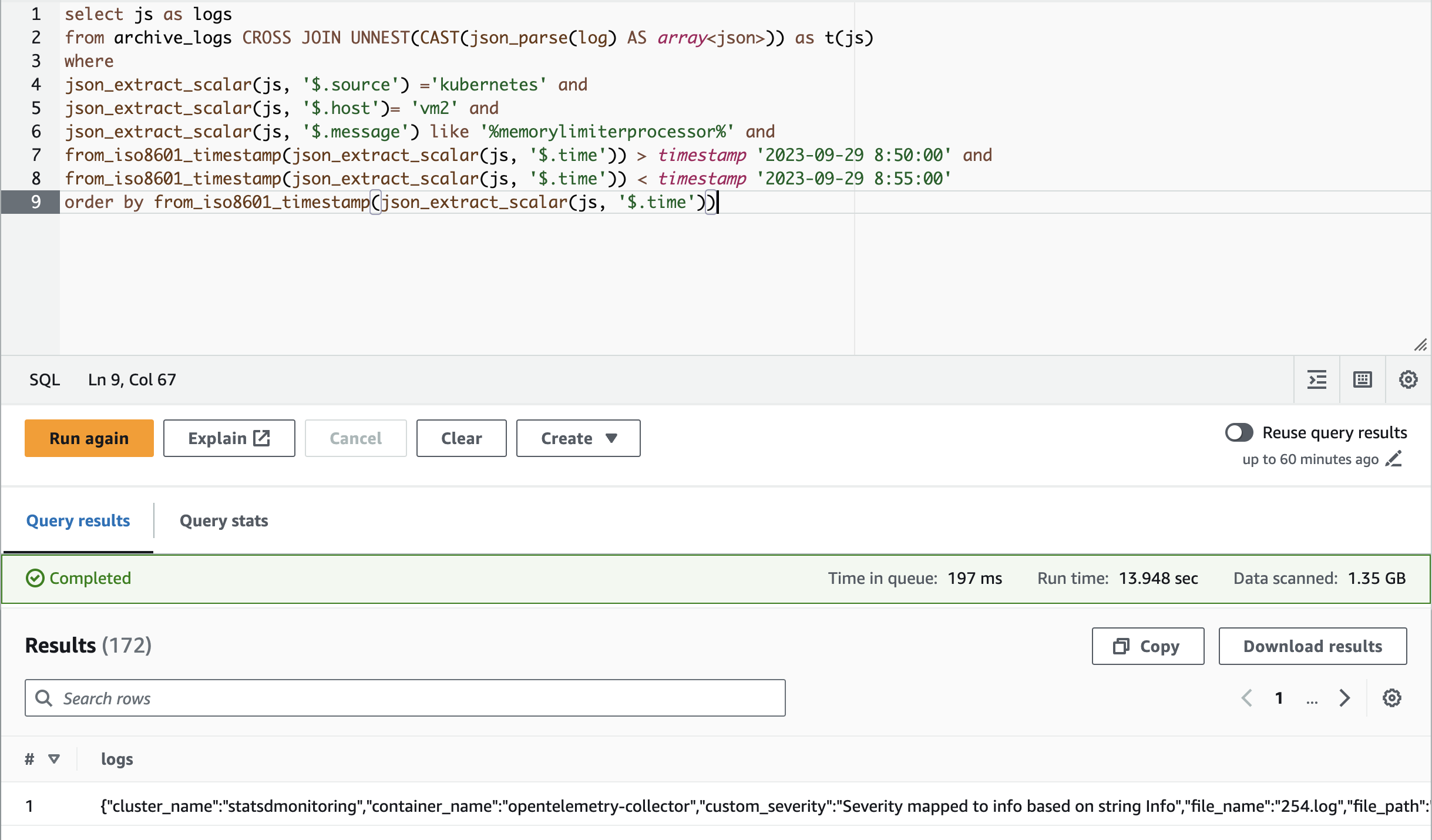
To query for Cloud logs, use the timestamp field instead of a time field to give a time range. The below query is used to fetch AWS logs related to a specific account in each time range.
select js
from archive_logs CROSS JOIN UNNEST(CAST(json_parse(log) AS array<json>)) as t(js)
where
from_unixtime(CAST(json_extract_scalar(js, '$.timestamp') AS bigint) /1000) > timestamp '2023-09-07 10:10:41' and
from_unixtime(CAST(json_extract_scalar(js, '$.timestamp') AS bigint) /1000) < timestamp '2023-09-07 10:14:41' and
json_extract_scalar(js, '$.accountNumber')='12345678'To get specific fields instead of the complete log payload, you can use the json_extract_scalar function against each field to fetch only those specified field data.
select
json_extract_scalar(js, '$.host') as host,
json_extract_scalar(js, '$.uid') as uid
from archive_logs CROSS JOIN UNNEST(CAST(json_parse(log) AS array<json>)) as t(js)
where
json_extract_scalar(js, '$.source') ='kubernetes' and
json_extract_scalar(js, '$.message') like '%memorylimiterprocessor%' and
from_iso8601_timestamp(json_extract_scalar(js, '$.time')) > timestamp '2023-09-29 8:50:00' and
from_iso8601_timestamp(json_extract_scalar(js, '$.time')) < timestamp '2023-09-29 8:55:00'
order by from_iso8601_timestamp(json_extract_scalar(js, '$.time'))View logs related to a particular time
- Log in to the AWS Management Console.
- Open the Amazon S3 console.
- In the left navigation pane, choose Buckets.
- In the bucket list, choose the name of the bucket that you configured to archive logs.
- Choose the archive folder.
- Choose the respective tenant folder and then the date folder.
- Choose a folder based on which hour of the day the log was ingested to OpsRamp.
Note:If a user configures the same bucket for multiple tenants, then you will have different directories for each tenant under the archive directory.